AWS CDK Best Practices: Clean Scalable Directory Structure
AWS Cloud Development Kit(CDK) is an open-source framework that lets us define cloud infrastructure in code—using programming languages like TypeScript, Python, and Java—and provision it thorough AWS CloudFormation.
Along with CDK comes a new problem: How to write code? Programming is art. We need to come up with a solution to a problem that cannot be solved mathematically. We are challenged.
Object oriented programming dates back to 1950s. Writing on the best practice of CDK deserves a series of books. This article only shows the practical directory structure of CDK project, aiming to be the compass that guides engineers throughout IaC voyage.
In CDK project, our own code are stored in the lib directory. So we only consider how to structure the lib.
Domain Structure
lib
├── config
│ └── stage-config.ts # class to handle configurations for multi-stage
├── domains # business domains such as payment, delivery
│ ├── domain-1
│ │ ├── domain-1-stack.ts
│ │ ├── action-1 # business operation unit
│ │ │ ├── resource-1.ts
│ │ │ └── resource-2.ts
│ │ ├── action-2
│ │ ├── config # domain level configuration for multi-stage
│ │ └── shared # resources shared across actions
│ └─ domain-2
├── infrastructure # utility domains used across business domains
│ ├── global # utility domains in us-east-1 region
│ │ ├── global-stack.ts
│ │ ├── config
│ │ ├── domain-1
│ │ │ ├── action-1
│ │ │ └── action-2
│ │ └── domain-2
│ └── shared # utility domains in main region
│ ├── shared-stack.ts
│ ├── config
│ ├── domain-1
│ └── domain-2
├── patterns # reusable constructs(L3 constructs)
│ ├── actions # action level reusable constructs
│ │ ├── action-pattern-1.ts
│ │ └── action-pattern-2.ts
│ └── domains # domain level reusable constructs
│ ├── domain-pattern-1.ts
│ └── domain-pattern-2.ts
└── stages # stage constructs for multi-stage
├── development-stage.ts
├── production-stage.ts
└── staging-stage.tsFile extension .ts in the tree is an example. Any file extension supported by CDK works as well.
Microservice architecture is a norm. We want to call this directory structure “service structure.” But the term “service” is confusing whether the word indicates AWS services like S3 or business services like payment. In software engineering the term “domain”, “business”, and “service” are used interchangeably. We could use “business” but engineers are familiar with domain-driven design. More engineers feel more comfortable with “domain” than with “business”.
Under the lib directory are: config, domains, infrastructure, patterns, stages.
Config
One challenge every team faces with CDK is to deploy infrastructure to multiple stages. We can do this by preparing the configuration for each stage and load the certain configuration based on the target stage.
See how to deploy CDK application to multiple stages from single codebase.
Domains
This is heart our CDK project. Domains can be payment, customer relation, delivery, shipping, marketing, and so on.
Although some domains might depend on other domain, each domain is to be independent. A domain, aggregated as a Stack, is a deployable unit.
Each domain contains some resources for its own actions. The great example of actions are CRUD. Actions under the same domain are like to share some of the same resources. The shared directory holds these resources.
When one domain becomes so intricate that engineers find themselves hard to modify infrastructure, we divide that domain into sub domains, or making part of the domain a new domain.
If our Lambda functions are written in other than TypeScript, we can save the Lambda function codes under the action directories. If, however, they are written in TypeScript, the additional consideration is required. See Deploy TypeScript Lambda with CDK.
Our decentralized configuration enables us domain-level configuration for multiple stages.
Infrastructure
The infrastructure directory consists of the global directory and the shared directory. The domains and resources under this directory work as utilities and helpers for the main domains.
The global stack and its resources are deployed to us-east-1 region due to AWS requirements. For example, the SSL certificate that is associated with CloudFront must be issued in us-east-1 region, regardless which region the CloudFront is deployed to.
The shared stack and its resources are deployed to the region of main domains. Resources in the shared stack are shared across the main domains.
The both global and shared stacks are deployed before the main domain stacks.
Patterns
As infrastructure grows, we see patterns in its structure. This directory is a storage for reusable constructs. Since we divide directories into domain and action levels, the reusable constructs are categorized as either domain or action.
We borrow the term “pattern” from the AWS’s official documentation.
Stages
Ideally, our infrastructures of all stages are identical, only different in the configuration. Nevertheless, the aim to reduce costs forces us to share some resources between non-production stages. For such a case, to control which stage deploys which resource, we have stages directory to holds multiple Stage constructs.
See Stage Construct and Stage Config about how to deploy different resources based on stage.
Directory Structure as Software Architecture
Directory structure and software architecture go hand in hand. The layered architecture is most popular. Let’s see how our directory structure fits in that.
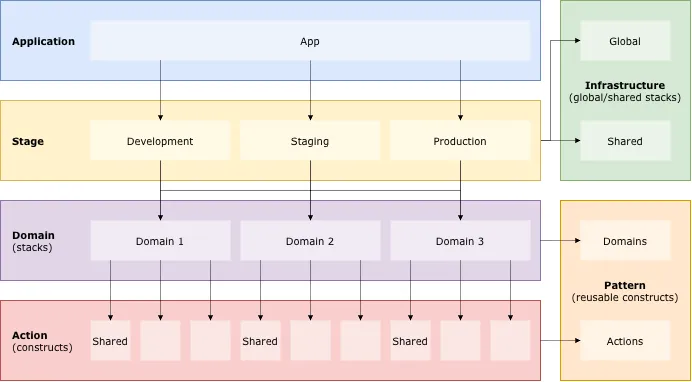
We have four main layers from Application to Stage, Domain, and to Action. Infrastructure and Pattern come sideway. The data flows from top to bottom, or to the side. The responsibility of each layer is same as the responsibility of directory.
Anti-Pattern: AWS Service Structure
lib
├── configs
│ ├── development.config.ts
│ ├── production.config.ts
│ └── staging.config.ts
├── constructs
│ ├── l2
│ │ ├── aws-service-1
│ │ │ ├── custom-construct-1.ts
│ │ │ └── custom-construct-2.ts
│ │ └── aws-service-2
│ │ ├── custom-construct-1.ts
│ │ └── custom-construct-2.ts
│ └── l3
│ ├── custom-construct-1.ts
│ └── custom-construct-2.ts
├── stacks
│ ├── stack-1
│ │ ├── ec2
│ │ │ ├── instance-1.ts
│ │ │ └── instance-2.ts
│ │ ├── rds
│ │ │ ├── database-1.ts
│ │ │ └── database-2.ts
│ │ ├── s3
│ │ │ ├── bucket-1.ts
│ │ │ └── bucket-2.ts
│ │ ├── stack-1.ts
│ │ └── vpc
│ │ ├── vpc-1.ts
│ │ └── vpc-2.ts
│ └── stack-2
│ ├── api-gateway
│ │ ├── http-api-1.ts
│ │ └── rest-api-1.ts
│ ├── event-bridge
│ │ ├── rule-1.ts
│ │ └── rule-2.ts
│ ├── lambda
│ │ ├── function-1.ts
│ │ └── function-2.ts
│ ├── sqs
│ │ ├── queue-1.ts
│ │ └── queue-2.ts
│ └── stack-2.ts
└── stages
├── development-stage.ts
├── production-stage.ts
└── staging-stage.tsEngineers are like to structure CDK directories by AWS service and by construct. This is like a MVC framework that forces us to organize our code into models, views, and controllers. Pattern-based structure works when the application is small. But as the application becomes bigger, we lose connection which model is associated with which controller. We learned that User model and UserController shall be colocated in the same directory.
Organization based on AWS service gives us an edge start. We will, however, lose momentum shortly.
After Thoughts
I recently launch my campaign website, infrastructure of which written with CDK. The best directory structure shown above was the outcome of that work.
Tips
Plan Big; Find Middle Ground
The hard part of IaC is that the resources are given IDs once we deploy infrastructure and we stick to those IDs. Changing an ID requires recreation of a new same type of resource. While computing resources are easier to replace, resources like databases and storages are not. Replacement of hard resources takes tremendous effort. Replacing construct ID for the sake of organization is stupid.
Plan ahead of construct ID, foresee how infrastructure evolves. Thorough plan that accords with business saves lots of time and money in future, although that slows down the project in short term.
On the other hand, too much forecasting has kills thousands of projects before. Hence we must find the middle ground. Nesting constructs makes interconnection between resources legible and manageable. Flatten constructs makes infrastructure flexible.
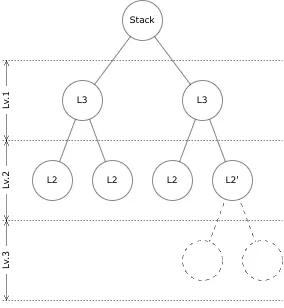
Think of nesting construct IDs, ignoring the App and the Stage. The root construct is a Stack. Beneath the stack come L3 constructs at level 1. One L3 construct comprises of L2 constructs. These comprised L2 constructs are located at level 2. Level 2 is the deepest level in most cases. Still, we prepare for situation in which we want to aggregate L2 constructs into a L3 construct under the L3 construct. This undertaking produces the level 3, and shall be a temporal solution.
More than 3-level depth of constructs under Stack is too restrictive and counter productive. Prefixing works as nesting, keeping margin for the interconnection yet to be emerged.
We hope that directory structure and construct IDs match. This hope is unrealistic. Directory structure is for programming purpose. Construct IDs are for CloudFormation. They are different issues. Do not handle them like they are same. Sometime they match. Sometime they don’t. Let it go.
Block Architecture
In the subsection Directory Structure as Software Architecture, I attempted to fit our directory structure into Clean Architecture. And I failed. The below is my illustration.

The lesson from Clean Architecture is this: external elements should depends on our business and application, not vice versa. CDK is a library, which is an external element for us. CDK never gets us Clean Architecture.
Yet I want to apply the lesson. I want architecture to focus on business operation instead of AWS resources. The layered architecture describes CDK project well but it does not grasp the lesson that our business is the most important.
Thus I invented new architecture called Block Architecture.
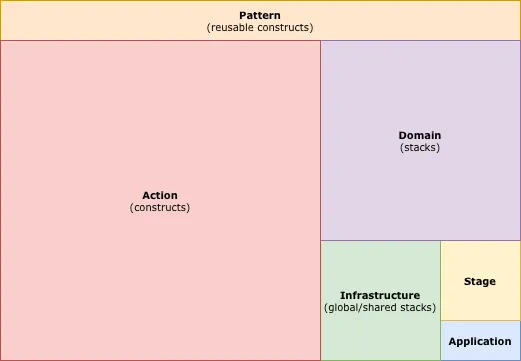
This illustration of architecture is influenced by golden rectangle.
We begin with the smallest block, Application. For convenience, Application block accounts for the first two square blocks. The block becomes larger in proportion, to which the side length of new block is equal to the sum of side lengths of the preceding two blocks. This produces a golden ratio in the side lengths of the current block and the previous block. Block architecture resembles the floor plan of physical architecture.
Usually, the square blocks are arranged to draw a golden spiral. Here, the first three blocks Application, Stages, and Infrastructure are rearranged so that the layout makes more sense. Application block is a front door; Stage block is a lobby, navigating us to Infrastructure or Domain blocks. Passing through Domain we reach to Action block, which is our goal. The last Action block is the largest. The area each block occupies indicates the importance of each block. The importance can be translated into the amount of code we write.
Pattern block is like a backyard storage, which provides necessary equipments to Actions and Domains.
I was going to call this architecture Golden Architecture. Then I found myself writing a word “block” many times in texts. A word “Golden” sounds exaggeration. Pattern block is an exceptional block that dees not follow the sequence. Calling “block”, software designers can make rectangles not just squares but any type of shapes.
In Block Architecture, only our imagination limits us.